
The ultimate platform for your data challenges. Without contest.
Features

Built-in Data Science
Studio
Full-fledged data science environment with VSCode and Jupyter.

Instant access to
datasets
Datasets instantly available as mounted volumes on the compute instances.
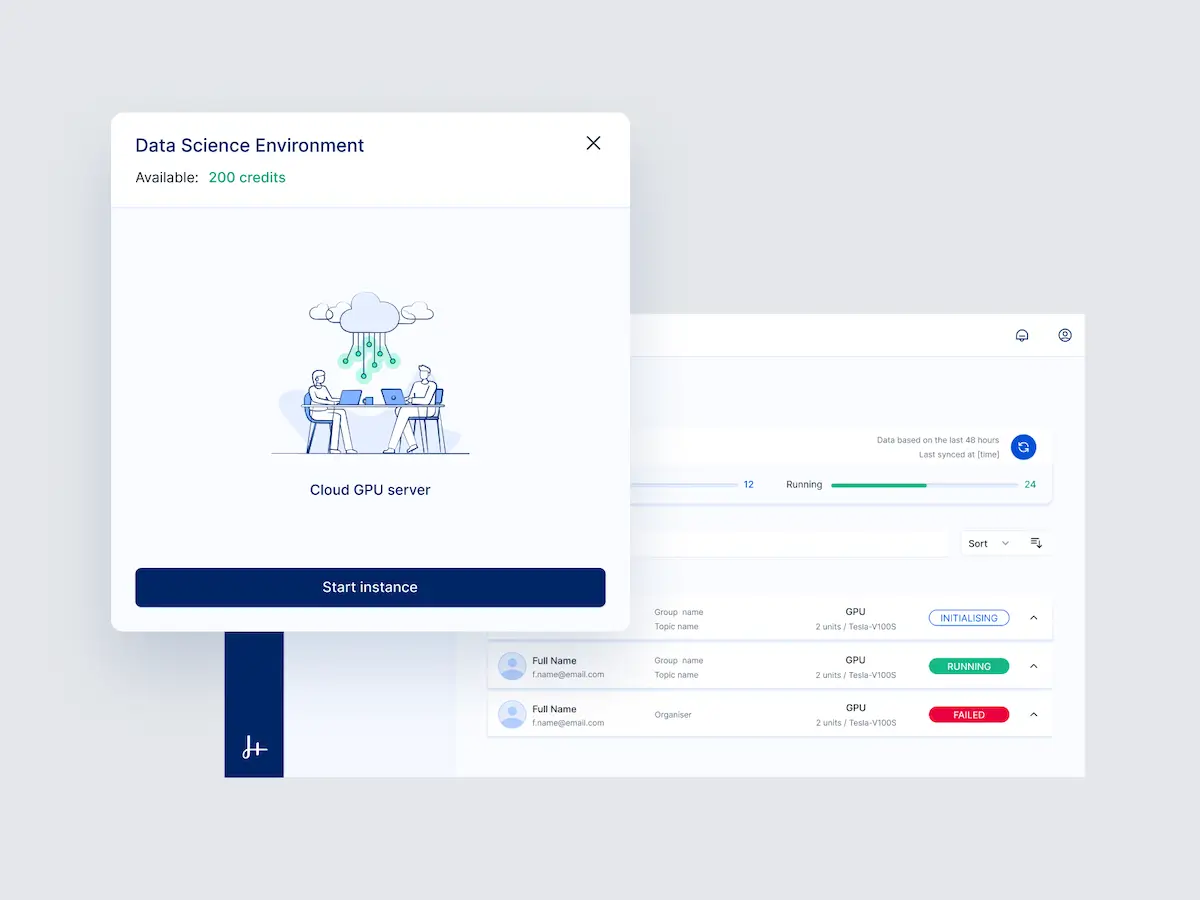
Access to GPU compute resources
Metered access to GPUs with automatic shut down of inactive instances.

Shared workspaces
Easy sharing of intermediary data results within participating groups.
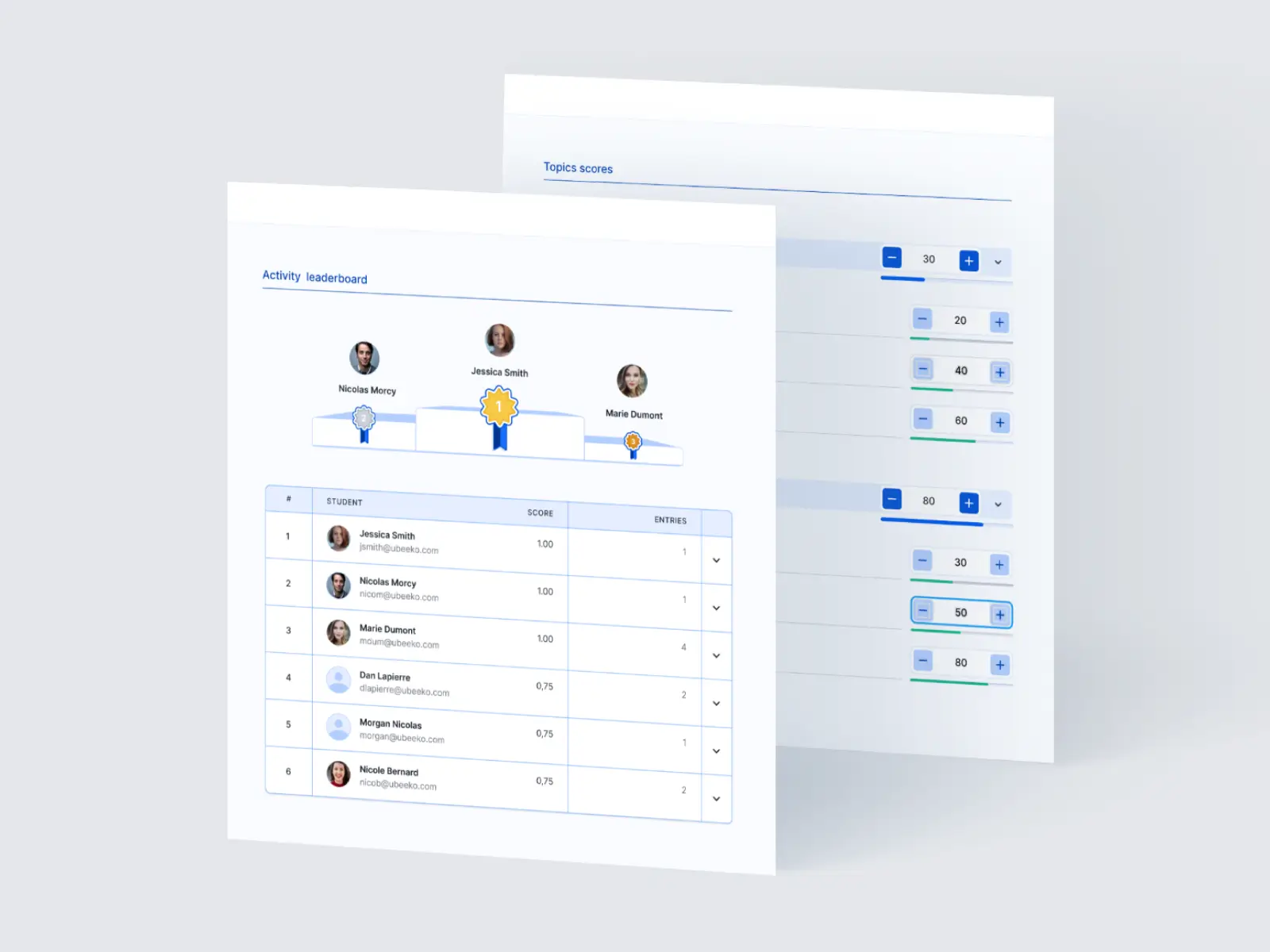
Code & model performance
scoring
Kaggle-like automated model scoring with preloaded scikit-learn metrics.

Real-time leaderboards
Embedded leaderboards for positive emulation across participants.
Data security and privacy

Set-up and collect NDAs
HFactory allows you to make the access to the datasets conditional to the prior signature of an NDA by participants. You can set up the entire process directly on the platform, making it easy to track signatures and to download proof of signature documents.

Work in a trusted compute environment
Choose from various security levels and traceability options based on dataset confidentiality and participant profiles. Options include utilising a 100% European compute infrastructure, prohibiting local downloads of the datasets or using an internal GitLab instance with SSO.